
Build a DNS Resolver in Python From Scratch
Recursive resolution, TTL caching, and the chain of responsibility pattern that powers every internet request you make

Every command you run hits DNS. Every curl, every kubectl, every terraform apply. Your browser made a DNS query to load this page. DNS is the most heavily used distributed system on the planet, and most engineers have never seen what happens inside a resolver.
Today we build one from scratch. A DNS resolver with TTL caching and the Chain of Responsibility pattern.
The 3-Question Framework
What does the system DO? It translates domain names into IP addresses by walking the DNS hierarchy. This is the Chain of Responsibility pattern. A request passes through a chain of handlers (cache, hosts file, recursive resolver) until one of them can answer it.
What operations must be FAST? Most DNS lookups should return instantly from cache. A dict with TTL gives us O(1) cache hits. Cache misses trigger network calls, which are slower but infrequent for popular domains.
What is the core LOGIC? Recursive resolution. Start at the root DNS servers. They point you to the TLD servers (.com, .io). The TLD servers point you to the authoritative servers. The authoritative server gives you the final IP address. Cache every answer with its TTL so you only walk the tree once.
Pattern: Chain of Responsibility (cache -> resolver -> root -> TLD -> auth)
Structure: dict with TTL (DNS cache)
Algorithm: Recursive resolution with caching at every level
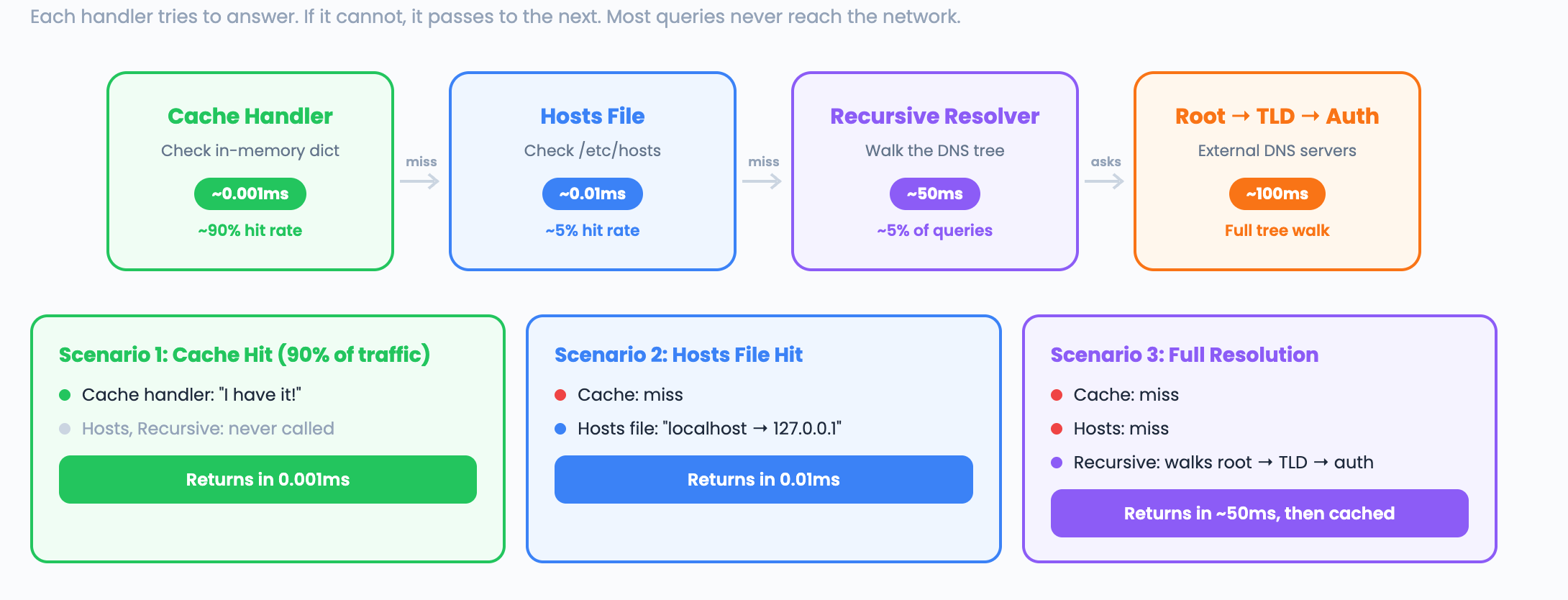
How DNS Resolution Actually Works
When you type crackthat.io in your browser, here is what happens:
This is a chain. Each handler either answers the question or passes it to the next handler in the chain. That is the Chain of Responsibility pattern.
The key insight: after the first lookup, Step 1 returns the answer instantly for the next 300 seconds. Without caching, every HTTP request would add 50 to 100ms walking the DNS tree.
Step 1: The DNS Cache
The foundation. A simple dict with TTL expiration. Same lazy expiration pattern from Issue 3.
import time
class DNSCache:
def __init__(self):
self._cache = {}
def get(self, domain, record_type="A"):
key = (domain, record_type)
entry = self._cache.get(key)
if entry is None:
return None
if time.time() > entry["expiry"]:
del self._cache[key]
return None
return entry["value"]
def put(self, domain, value, ttl, record_type="A"):
key = (domain, record_type)
self._cache[key] = {
"value": value,
"expiry": time.time() + ttl,
}
def size(self):
return len(self._cache)
Interview phrasing: “The DNS cache is a hash map keyed by (domain, record_type) with lazy TTL expiration. Same pattern as Redis. O(1) lookups. Expired entries are cleaned up on access.”
Step 2: The Resolver
The resolver sends a query to a DNS server and returns the IP address. We use Python’s socket library to make the actual network call.
import socket
class DNSResolver:
def __init__(self):
self.cache = DNSCache()
self._queries = 0
def resolve(self, domain):
cached = self.cache.get(domain)
if cached:
return cached
ip = self._do_lookup(domain)
if ip:
self.cache.put(domain, ip, 300)
return ip
def _do_lookup(self, domain):
self._queries += 1
try:
result = socket.getaddrinfo(domain, None, socket.AF_INET)
if result:
return result[0][4][0]
except socket.gaierror:
return None
return None
def stats(self):
return {
"cache_size": self.cache.size(),
"queries_made": self._queries,
}
On the first call, the resolver makes a real DNS query using the operating system’s resolver. The result is cached for 300 seconds. Every subsequent call for the same domain returns instantly from cache.
In production DNS servers like CoreDNS or Unbound, the resolver builds raw UDP packets and walks the tree from root servers to authoritative servers. Our implementation delegates to the OS for simplicity, but the caching and chain of responsibility architecture is identical.
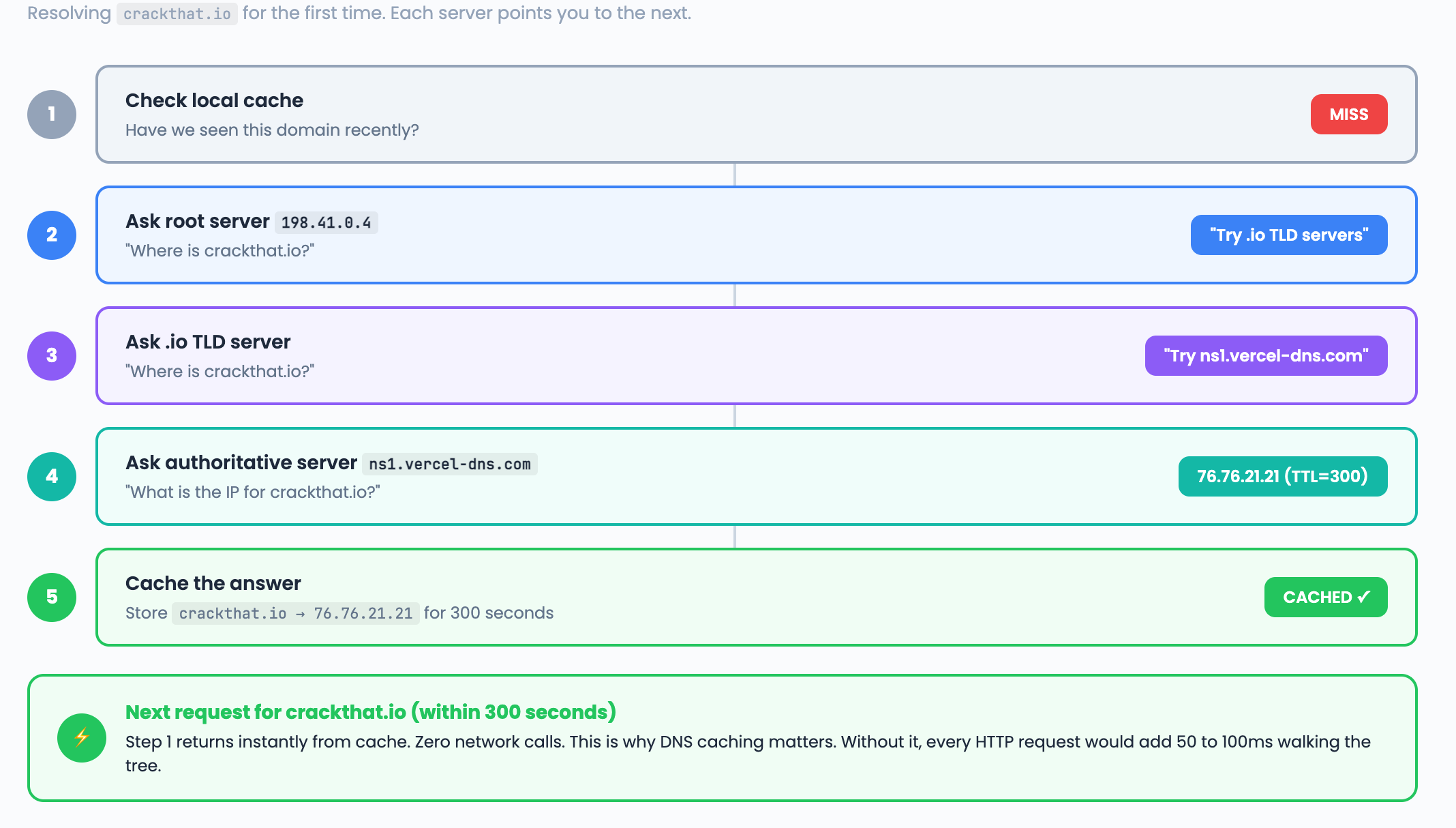
How production recursive resolution works:
Ask root server for crackthat.io
Root says “Try the .io TLD servers”
Ask .io TLD server for crackthat.io
TLD says “The authoritative server is ns1.vercel-dns.com”
Ask authoritative server for crackthat.io
Authoritative says “76.76.21.21” with TTL=300
Cache the answer and return the IP
Step 3: The Chain of Responsibility
The Chain of Responsibility pattern makes the resolver extensible. Each handler tries to answer the query. If it cannot, it passes to the next handler.
from abc import ABC, abstractmethod
class DNSHandler(ABC):
def __init__(self):
self._next = None
def set_next(self, handler):
self._next = handler
return handler
def pass_to_next(self, domain):
if self._next:
return self._next.handle(domain)
return None
@abstractmethod
def handle(self, domain):
pass
class CacheHandler(DNSHandler):
def __init__(self, cache):
super().__init__()
self._cache = cache
def handle(self, domain):
result = self._cache.get(domain)
if result:
return result
return self.pass_to_next(domain)
class HostsFileHandler(DNSHandler):
"""Check local host mappings before going to network."""
def __init__(self, hosts_path=None):
super().__init__()
import os
if hosts_path is None:
hosts_path = os.path.join(os.sep, "etc", "hosts")
self._hosts = self._load_hosts(hosts_path)
def _load_hosts(self, path):
hosts = {}
try:
with open(path) as f:
for line in f:
line = line.strip()
if line and not line.startswith("#"):
parts = line.split()
if len(parts) >= 2:
ip = parts[0]
for hostname in parts[1:]:
hosts[hostname] = ip
except FileNotFoundError:
pass
return hosts
def handle(self, domain):
result = self._hosts.get(domain)
if result:
return result
return self.pass_to_next(domain)
class RecursiveHandler(DNSHandler):
def __init__(self, resolver):
super().__init__()
self._resolver = resolver
def handle(self, domain):
return self._resolver.resolve(domain)
Now we wire the chain together:
def build_resolver_chain():
cache = DNSCache()
resolver = DNSResolver()
resolver.cache = cache
cache_handler = CacheHandler(cache)
hosts_handler = HostsFileHandler()
recursive_handler = RecursiveHandler(resolver)
cache_handler.set_next(hosts_handler).set_next(recursive_handler)
return cache_handler
chain = build_resolver_chain()
ip = chain.handle("crackthat.io")
print(f"crackthat.io resolved to {ip}")
Why the chain matters:
Most queries hit the cache handler and return in microseconds. Only cache misses reach the hosts file handler. Only misses from both reach the recursive handler which makes network calls. This is the same layered lookup your operating system uses:
Application DNS cache (Chrome, Firefox)
OS resolver cache (the local hosts file, systemd-resolved)
Local recursive resolver (CoreDNS, dnsmasq)
Upstream recursive resolver (8.8.8.8, 1.1.1.1)
Root servers to TLD to Authoritative
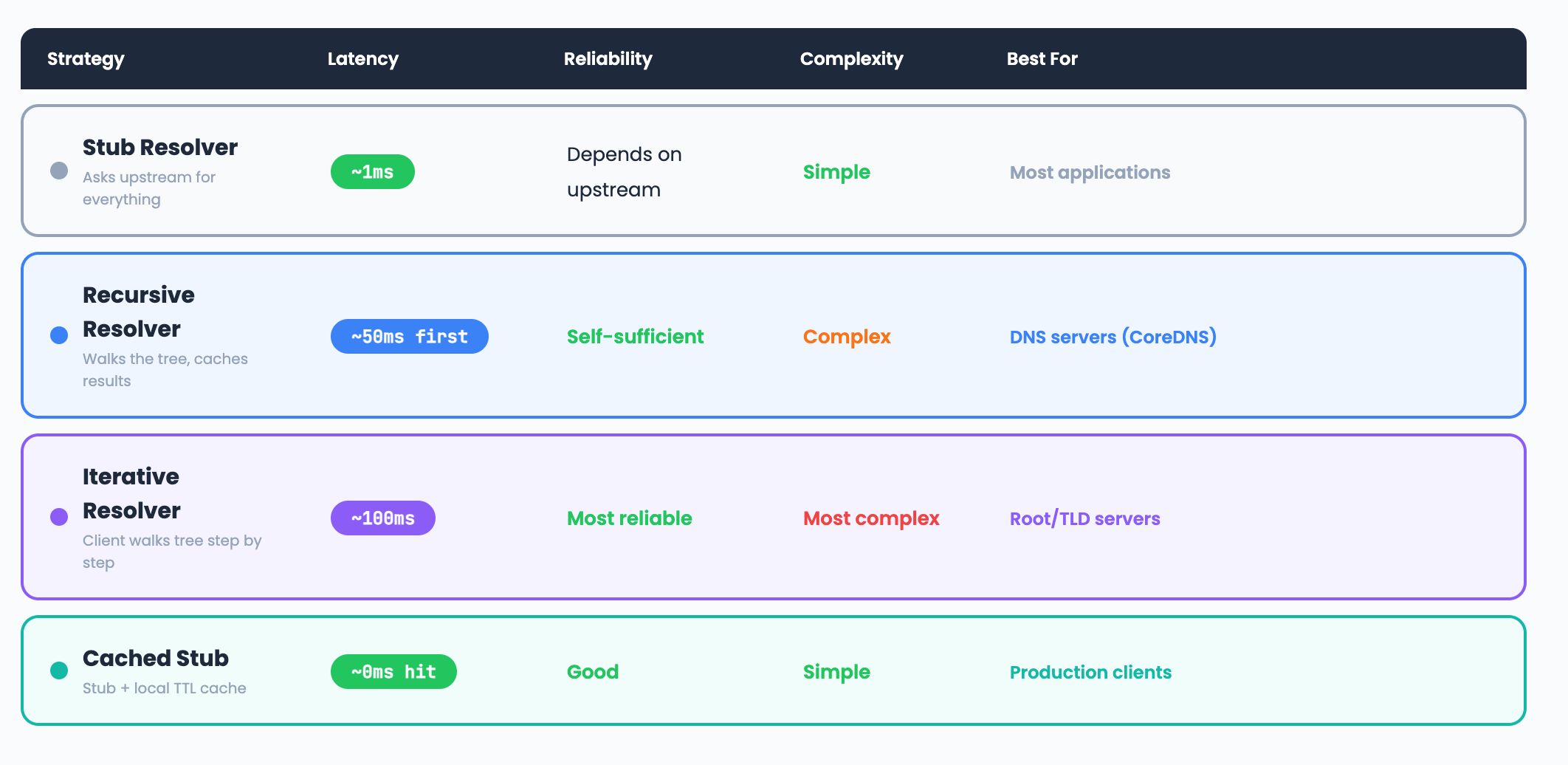
Comparison: DNS Resolution Strategies
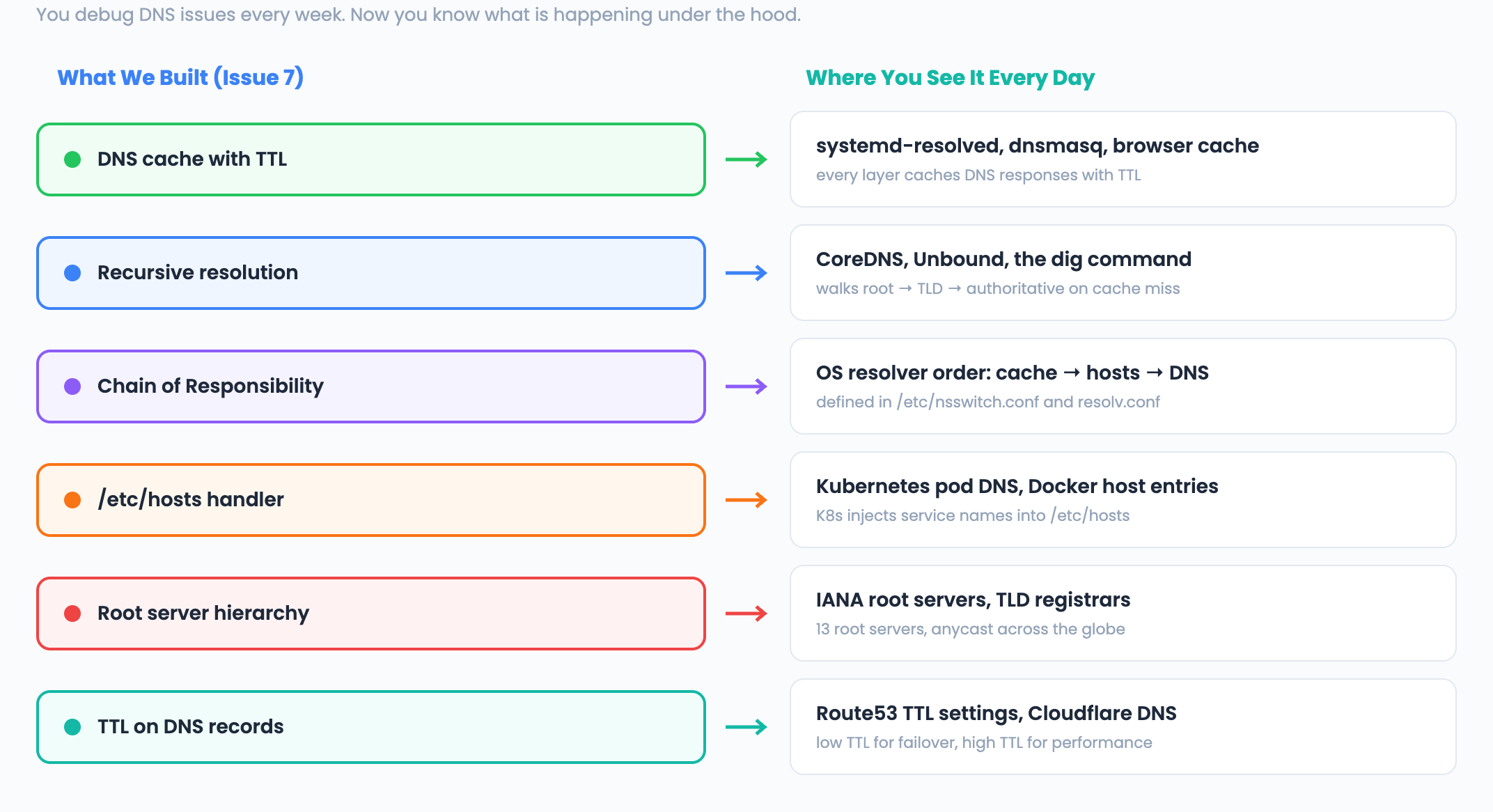
The DevOps Connection
Scaling to Millions: DNS at Production Scale
Our resolver handles one machine. Production DNS serves billions of queries per day across the globe. Here is how it scales.
Anycast Routing
Every root DNS server has one IP address, but that IP is announced from dozens of locations worldwide. When you query 198.41.0.4, your packets go to the nearest physical server. This is called anycast. Cloudflare uses the same technique for their 1.1.1.1 resolver. One IP, 300+ locations. Your query never crosses the ocean.
GeoDNS
A single domain can return different IP addresses based on where the client is. A user in Dubai gets routed to a server in the Middle East. A user in London gets routed to a server in Europe. Route53, Cloudflare, and Akamai all support this. It is how CDNs deliver content from the closest edge node.
Caching Hierarchy
Production DNS uses multiple layers of caching to absorb traffic before it reaches authoritative servers.
Browser cache (Chrome, Firefox)
-> OS cache (systemd-resolved)
-> Local resolver (CoreDNS in your K8s cluster)
-> ISP resolver (your provider's DNS)
-> Authoritative server (only on full miss)Each layer absorbs 80 to 90% of queries. By the time a request reaches the authoritative server, it represents thousands of identical queries that were served from cache.
Negative Caching
Production resolvers also cache “domain not found” responses (NXDOMAIN). Without this, a typo like “gogle.com” would hit the authoritative server on every single request. Negative caching with a short TTL (30 to 60 seconds) prevents this.
DNS Failover and Health Checks
Route53 and Cloudflare support health checked DNS records. If a server fails its health check, the DNS record is automatically updated to point to a healthy server. The TTL on these records is kept low (30 to 60 seconds) so clients pick up the change quickly.
Normal: api.example.com -> 10.0.0.1 (healthy)
Failover: api.example.com -> 10.0.0.2 (backup)
Recovery: api.example.com -> 10.0.0.1 (restored)This is the foundation of active/passive failover. Your Terraform configs probably already use this pattern.
Rate Limiting DNS Servers
At scale, DNS servers must protect themselves from abuse. Techniques include response rate limiting (RRL) to cap the number of identical responses per second, and query rate limiting per source IP. Without these, a DNS amplification attack can take down your resolver.
Interview upgrade: When the interviewer asks about DNS, mention anycast for global distribution, caching hierarchy for traffic absorption, and health checked records for failover. This shows you think at production scale, not just single machine implementations.
Interview Walkthrough Script
When the interviewer asks “Design a DNS resolver”:
“I would use the Chain of Responsibility pattern. A DNS query passes through a chain of handlers: first the local cache for O(1) lookups, then the hosts file, then a recursive resolver. The recursive resolver walks the DNS tree starting at root servers, following referrals through TLD servers to the authoritative server. Every response is cached with its TTL. Most production traffic hits the cache and returns in microseconds. For reliability I would add retry logic, multiple root servers, and negative caching for NXDOMAIN responses.”
Challenge: Try It Yourself
CNAME resolution. Add support for CNAME records. When you get a CNAME instead of an A record, resolve the CNAME target recursively.
Negative caching. Cache NXDOMAIN (domain not found) responses too. This prevents repeated lookups for nonexistent domains.
Benchmark cache hit rates. Resolve 1000 random domains, then resolve them again. Measure the hit rate and time difference.
Next week: Build a Task Queue in Python (Priority Queue)
Previous: Build a Load Balancer | Build a Rate Limiter | The GIL Explained