
Build a Rate Limiter From Scratch in Python
Three algorithms, one deque, and the trade-off every API gateway makes — sliding window vs token bucket, explained for interviews

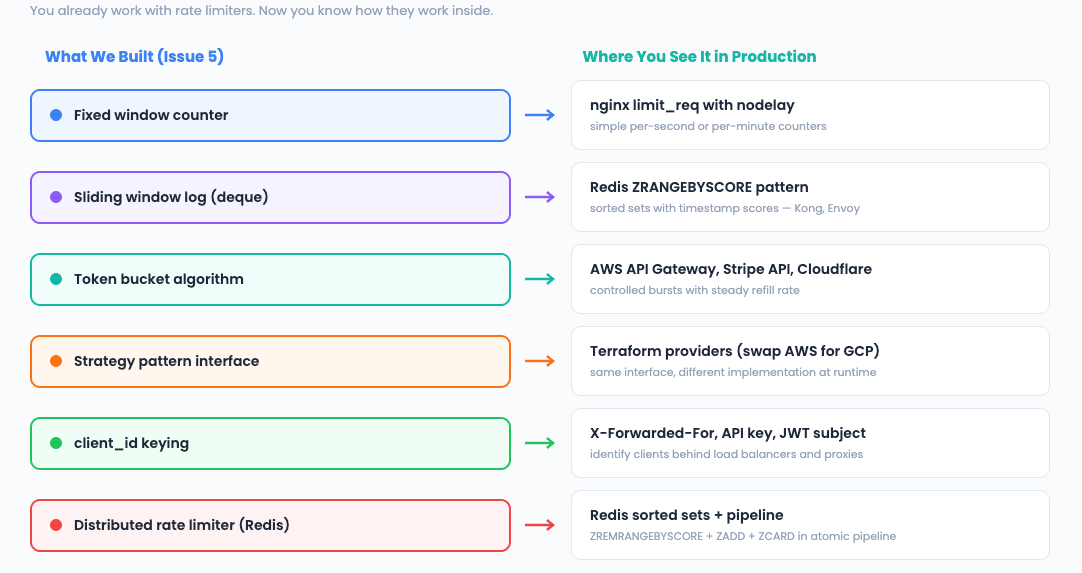
You have used rate limiters every day of your career. nginx limit_req. AWS API Gateway throttling. Redis-backed middleware. Cloudflare’s DDoS protection. But have you ever built one?
Today we build three rate limiting algorithms from scratch in Python — and learn why “100 requests per minute” is a harder problem than it sounds.
The 3-Question Framework
What does the system DO? It decides whether to allow or reject a request based on the number of requests a client has made recently. This is the Strategy pattern — we can swap algorithms (fixed window, sliding window, token bucket) at runtime without changing the caller.
What operations must be FAST? Every single request hits the rate limiter. It must decide to allow/deny in O(1). We cannot afford to scan all past requests.
A deque gives us O(1) append and O(1) popleft — perfect for maintaining a sliding window of timestamps.
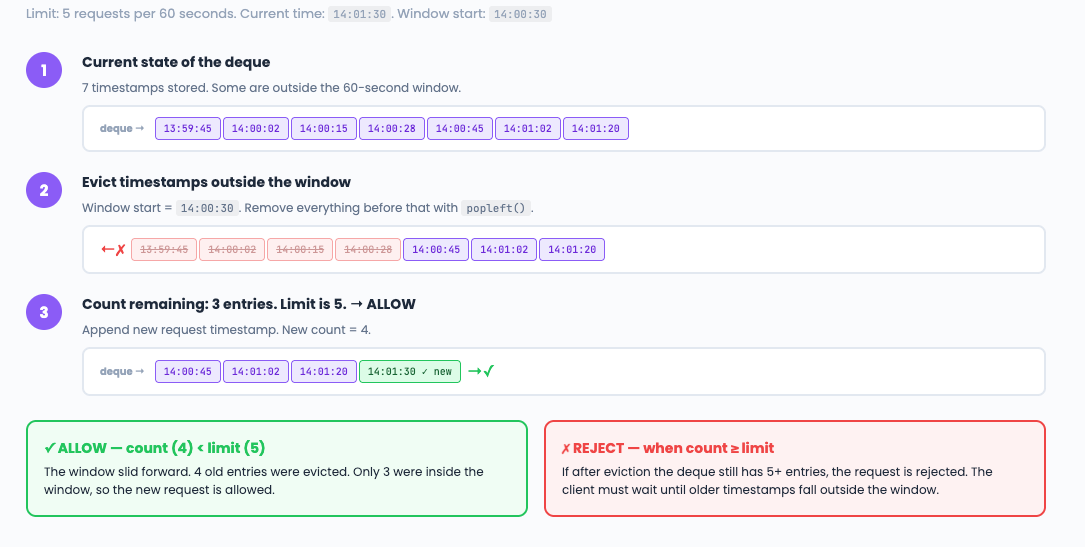
What is the core LOGIC? The sliding window log: store each request’s timestamp in a deque.
On every new request, evict timestamps outside the window, then count what remains. If count >= limit, reject.
Pattern: Strategy (swap algorithms at runtime)
Structure: deque (sliding window of timestamps)
Algorithm: Sliding window log — evict old, count remaining
Why “100 Requests Per Minute” Is Harder Than It Sounds
The naive approach, fixed window and it has a fatal flaw:
Imagine a limit of 100 requests per minute, with windows at :00 and :01.
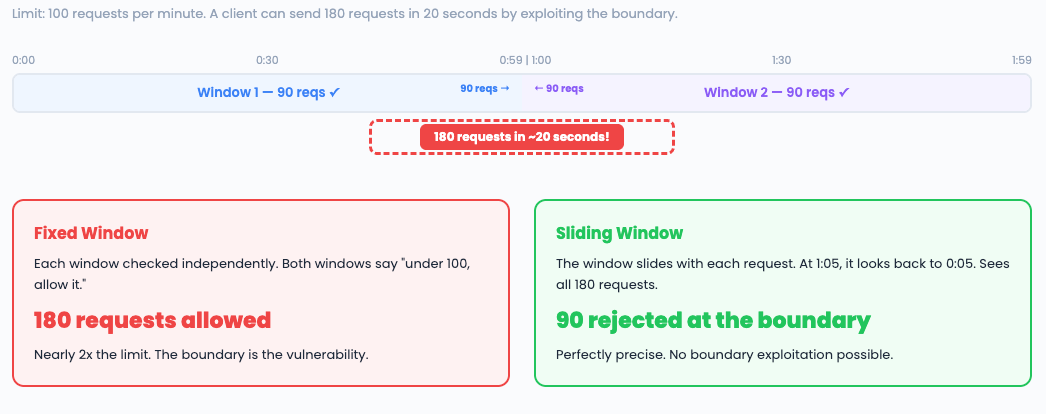
The boundary between windows creates a burst vulnerability. This is why every production rate limiter uses sliding windows or token buckets instead.
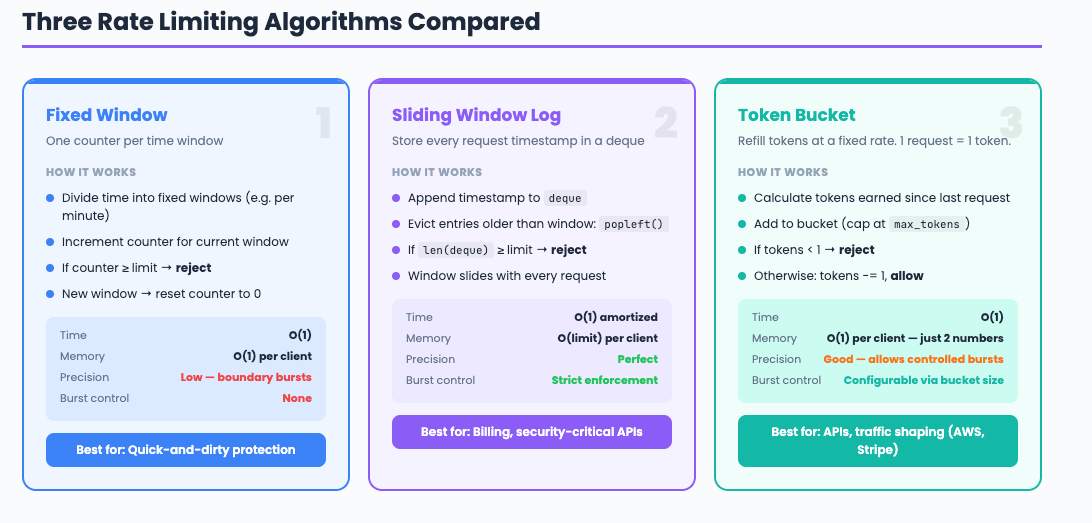
Strategy 1: Fixed Window Counter
The simplest approach. Fast, memory-efficient, but vulnerable to boundary bursts.
import time
from collections import defaultdict
class FixedWindowLimiter:
"""Count requests per fixed time window."""
def __init__(self, max_requests: int, window_seconds: int):
self.max_requests = max_requests
self.window_seconds = window_seconds
self._counters = defaultdict(lambda: {"count": 0, "window_start": 0})
def allow(self, client_id: str) -> bool:
now = time.time()
entry = self._counters[client_id]
window_start = now - (now % self.window_seconds)
if entry["window_start"] != window_start:
entry["count"] = 0
entry["window_start"] = window_start
if entry["count"] >= self.max_requests:
return False
entry["count"] += 1
return True
Complexity: O(1) time, O(n) space where n = number of clients.
Interview phrasing: “Fixed window is the simplest rate limiter — one counter per window per client.
It fails at window boundaries where a burst can exceed the limit by nearly 2x. Good enough for rough protection, not for strict enforcement.”
Strategy 2: Sliding Window Log
The precise approach. Stores every request timestamp. No boundary problem.
import time
from collections import defaultdict, deque
class SlidingWindowLogLimiter:
"""Track exact timestamps in a deque. Precise but memory-heavy."""
def __init__(self, max_requests: int, window_seconds: int):
self.max_requests = max_requests
self.window_seconds = window_seconds
self._requests = defaultdict(deque)
def allow(self, client_id: str) -> bool:
now = time.time()
window_start = now - self.window_seconds
req_log = self._requests[client_id]
# Evict timestamps outside the window
while req_log and req_log[0] <= window_start:
req_log.popleft()
if len(req_log) >= self.max_requests:
return False
req_log.append(now)
return True
Complexity: O(1) amortized (each timestamp is appended once, popped once). Space: O(max_requests * clients).
Interview phrasing: “The sliding window log stores every request timestamp in a deque. On each request, evict entries older than the window, then check the count. It is perfectly precise — no boundary bursts. The trade-off is memory: if you allow 10,000 requests per minute, you store 10,000 timestamps per client.”
Strategy 3: Token Bucket
The flexible approach. Allows controlled bursts. Used by AWS, Stripe, and most API gateways.
import time
class TokenBucketLimiter:
"""Refill tokens at a fixed rate. Each request costs one token."""
def __init__(self, max_tokens: int, refill_rate: float):
self.max_tokens = max_tokens
self.refill_rate = refill_rate # tokens per second
self._buckets = {}
def allow(self, client_id: str) -> bool:
now = time.time()
if client_id not in self._buckets:
self._buckets[client_id] = {
"tokens": self.max_tokens,
"last_refill": now,
}
bucket = self._buckets[client_id]
# Refill tokens based on elapsed time
elapsed = now - bucket["last_refill"]
bucket["tokens"] = min(
self.max_tokens,
bucket["tokens"] + elapsed * self.refill_rate,
)
bucket["last_refill"] = now
if bucket["tokens"] < 1:
return False
bucket["tokens"] -= 1
return True
Complexity: O(1) time, O(1) space per client (just two numbers: token count + last refill time).
Interview phrasing: “Token bucket refills at a constant rate and allows bursts up to the bucket size. It is the most memory-efficient — just two numbers per client.
AWS and Stripe use it because it naturally shapes traffic: steady traffic gets steady throughput, while short bursts are absorbed by the bucket.
The trade-off: less precise than sliding window, but much more memory-efficient at scale.”
Strategy Pattern: Swap Algorithms at Runtime
The real power: wrap all three behind one interface so you can switch algorithms without changing any caller code.
from abc import ABC, abstractmethod
class RateLimiter(ABC):
@abstractmethod
def allow(self, client_id: str) -> bool:
pass
class FixedWindowLimiter(RateLimiter):
# ... (implementation above)
pass
class SlidingWindowLogLimiter(RateLimiter):
# ... (implementation above)
pass
class TokenBucketLimiter(RateLimiter):
# ... (implementation above)
pass
# Swap at runtime — no caller changes needed
limiter: RateLimiter = SlidingWindowLogLimiter(100, 60)
# Later: limiter = TokenBucketLimiter(100, 100/60)
This is the Strategy pattern — the same pattern behind Terraform’s provider system (swap AWS for GCP), nginx’s load balancing (swap round-robin for least-connections), and Kubernetes’ scheduler (swap scoring plugins).
Comparison: When to Use What
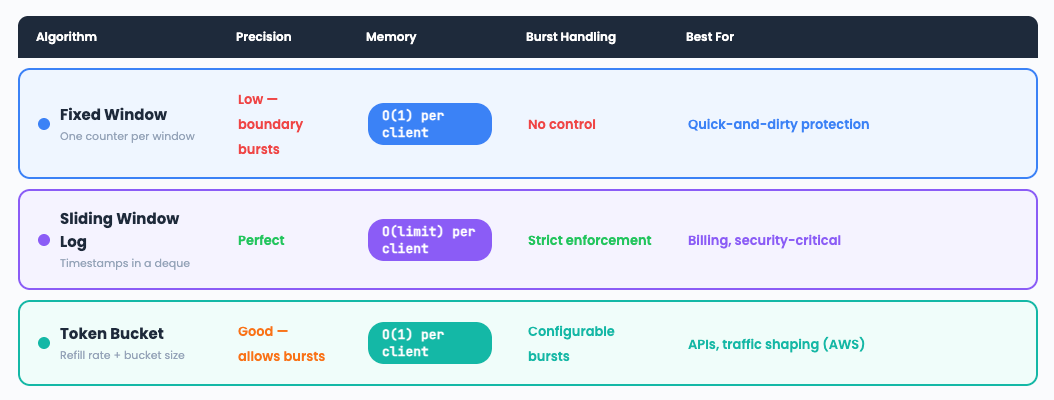
The DevOps Connection
Scaling to Distributed Systems
Our single-process implementation works for one server. In production with multiple servers, you need shared state:
# Distributed sliding window using Redis sorted sets
import redis
import time
class DistributedSlidingWindow:
def __init__(self, redis_client, max_requests, window_seconds):
self.r = redis_client
self.max = max_requests
self.window = window_seconds
def allow(self, client_id: str) -> bool:
key = f"ratelimit:{client_id}"
now = time.time()
window_start = now - self.window
pipe = self.r.pipeline()
pipe.zremrangebyscore(key, 0, window_start) # evict old
pipe.zadd(key, {str(now): now}) # add current
pipe.zcard(key) # count
pipe.expire(key, self.window + 1) # auto-cleanup
results = pipe.execute()
return results[2] <= self.max
Interview phrasing: “For distributed rate limiting, I would use Redis sorted sets. Each request adds a member with score = timestamp. ZREMRANGEBYSCORE removes old entries, ZCARD counts remaining.
The pipeline makes it atomic. This is the standard pattern used by Kong, Envoy, and most API gateways.”
Interview Walkthrough Script
When the interviewer asks “Design a rate limiter”:
“I would use the Strategy pattern to support multiple algorithms behind one interface. For the default, I would pick sliding window log — store timestamps in a deque, evict entries outside the window on each request, reject if count exceeds the limit. It is O(1) amortized and perfectly precise. If memory is a concern at scale, I would switch to token bucket — just two numbers per client, allows controlled bursts, which is what AWS and Stripe use. For distributed systems, Redis sorted sets give us the sliding window pattern with atomic pipelines.”
Challenge: Try It Yourself
Add HTTP headers. Return
X-RateLimit-Limit,X-RateLimit-Remaining, andX-RateLimit-Resetheaders — these are the standard rate limit response headers.Sliding window counter. Implement the hybrid approach — weight the previous window’s count by the overlap percentage. More precise than fixed window, less memory than sliding log.
Multi-tier limits. Implement rate limiting with multiple windows: 10 per second AND 100 per minute AND 1,000 per hour.
Next week: Build a Load Balancer in Python
Previous: The GIL Explained | TTL & Key Expiry | Redis Persistence | Build Your Own Redis