
Implement TTL and Key Expiry in Python From Scratch
Two expiration strategies, one min-heap, and the clever trick Redis uses to expire millions of keys without freezing

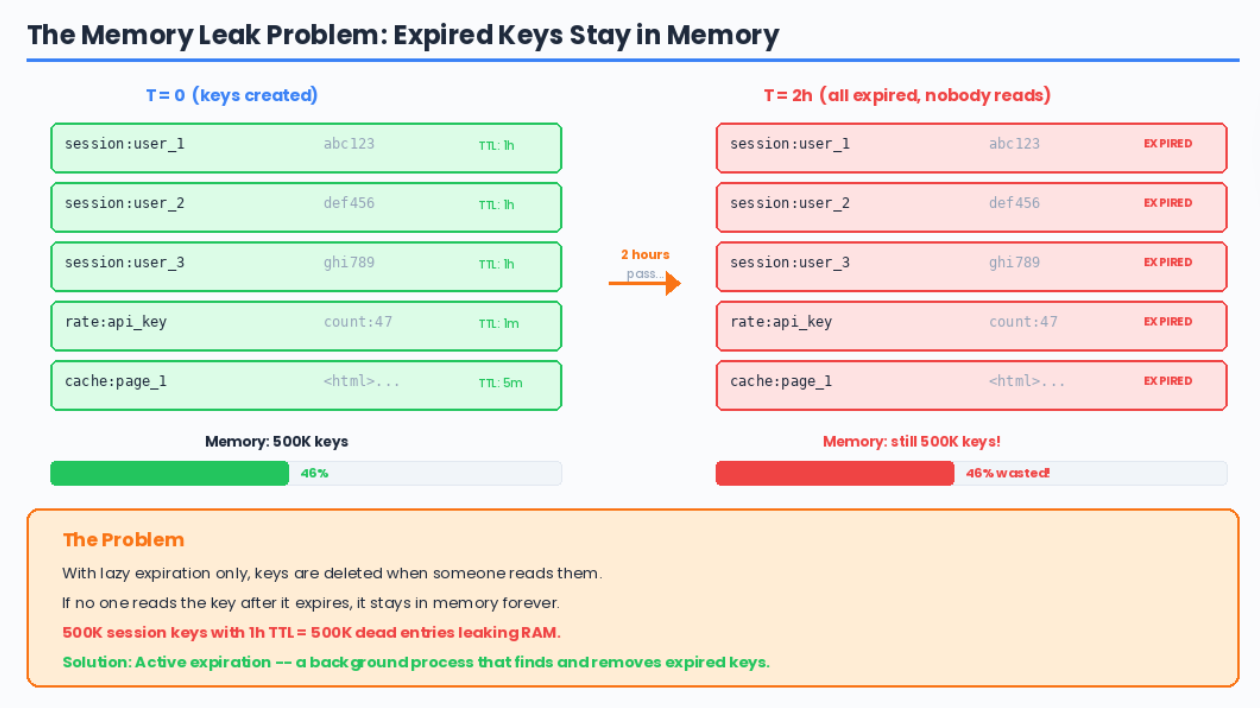
In Issue 1, we built a key-value store with basic TTL support. In Issue 2, we made it survive crashes. But there is a problem we have not solved yet.
When a key expires, it remains in memory. Our lazy expiration only removes it when someone asks for it. What about the millions of keys nobody ever reads again? They are just leaking memory. Forever.
Today, we fix that by building two expiration strategies from scratch.
The 3-Question Framework
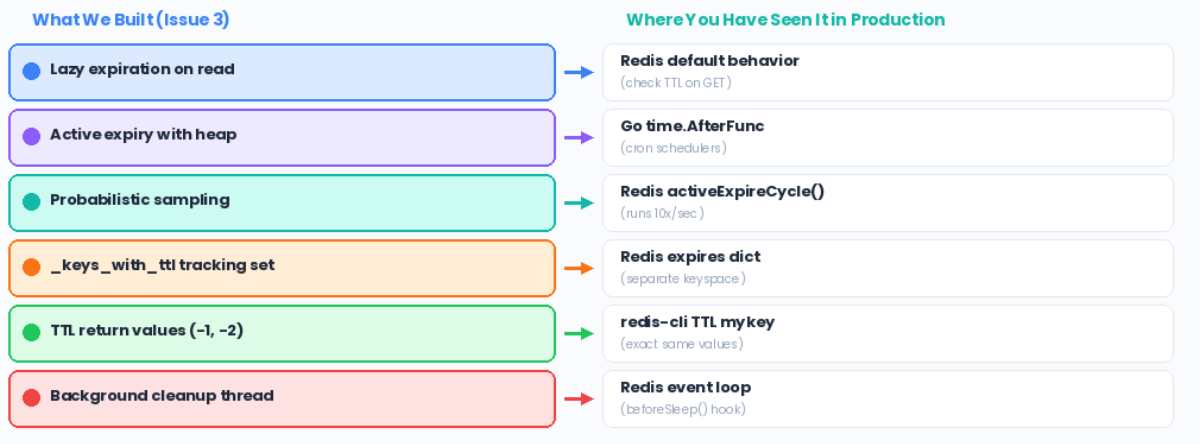
What does the system DO? It monitors all keys with a TTL and removes them when they expire. This is the Observer pattern.
What operations must be FAST? Find the next key to expire instantly. Min-heap (heapq) -- earliest expiry always on top.
What is the core LOGIC? Two complementary algorithms:
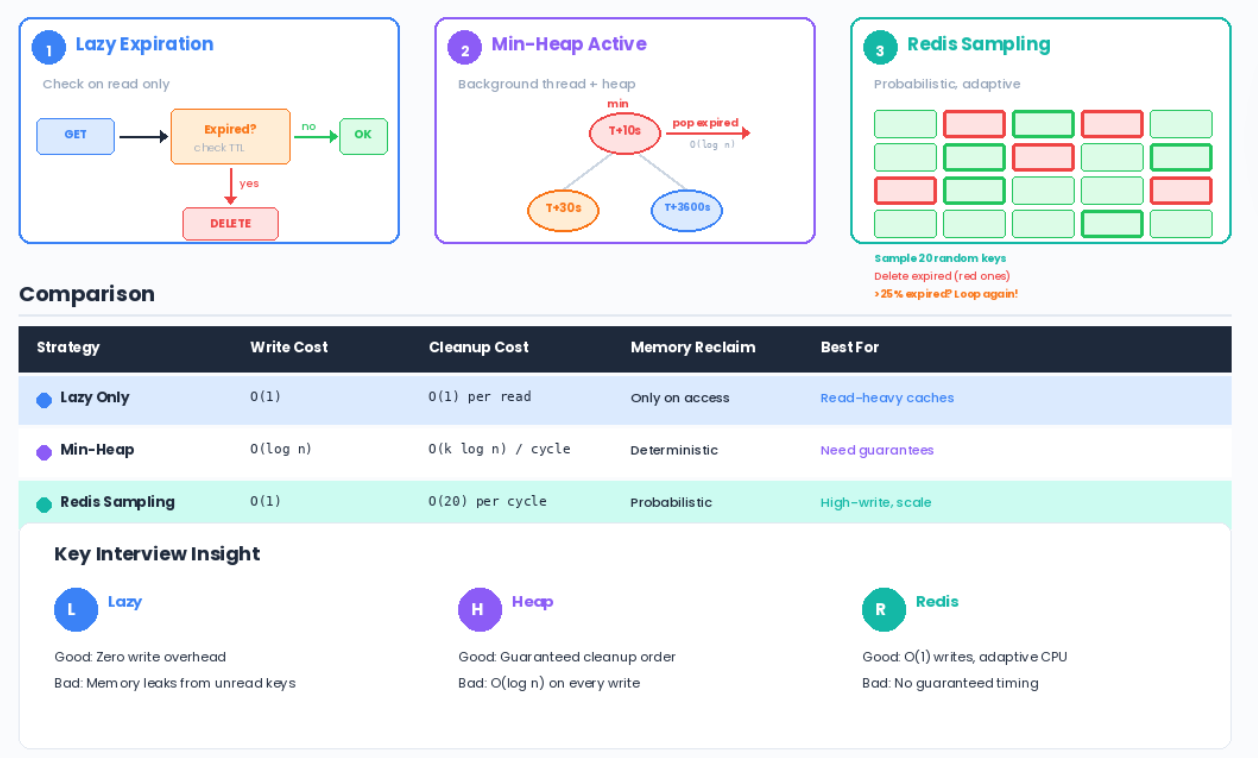
Lazy expiration: Check on read. If expired, delete it. O(1) per read.
Active expiration: Background process using a min-heap to proactively remove expired keys.
Strategy 1: Lazy Expiration (The Baseline)
Check TTL on every GET. If expired, delete and return None. Zero write overhead, but dead keys stay in memory if never read.
Interview phrasing: Lazy expiration is ideal when most keys get read at least once after their TTL. It falls apart with write-heavy workloads where keys are never read again.
Strategy 2: Active Expiration with a Min-Heap
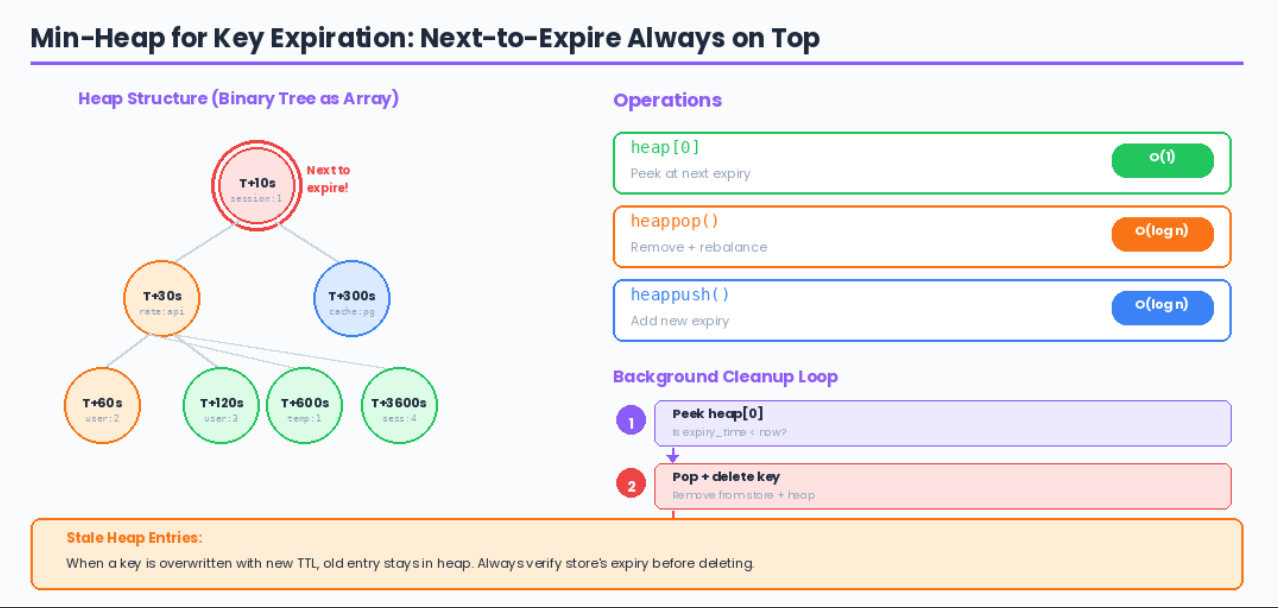
A min-heap keeps the next-to-expire key at position 0. Background thread polls the heap and removes expired keys.
heappush: O(log n) -- add new expiry
heappop: O(log n) -- remove the minimum
heap[0]: O(1) -- peek at next expiry
Watch out for stale heap entries: when a key is overwritten with a new TTL, the old entry stays in the heap. Always verify the store current expiry matches before deleting.
Strategy 3: Redis-Style Probabilistic Sampling
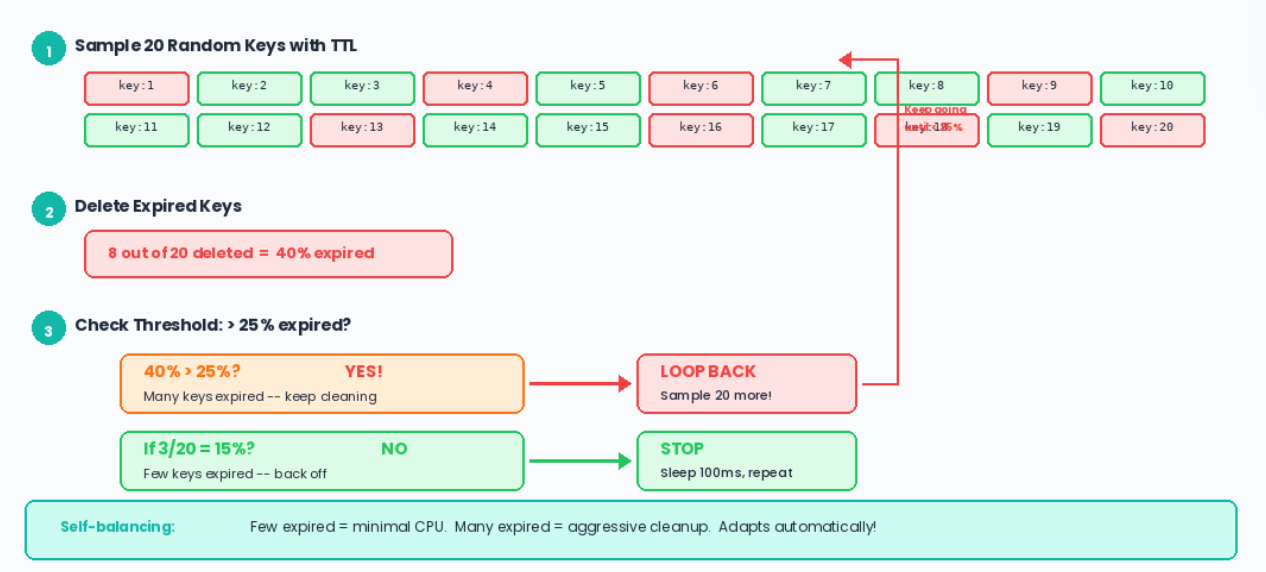
Redis runs this algorithm 10 times per second:
Pick 20 random keys that have a TTL
Delete the ones that are expired
If more than 25 percent were expired, go back to step 1
Otherwise, stop until next cycle
This is adaptive -- few expired keys means minimal CPU, many expired keys means aggressive cleanup. Self-balancing.
Interview phrasing: Redis avoids maintaining a sorted structure for expiry because it would add O(log n) overhead to every write. Instead, it uses probabilistic sampling that is statistically guaranteed to converge.
Comparison: When to Use What

The DevOps Connection
Interview Walkthrough Script
I would use two complementary strategies: lazy and active expiration. Lazy checks on every read.
But lazy alone leaks memory for unread keys. So I would add active expiration, either a min-heap for deterministic cleanup, or Redis-style probabilistic sampling for scale. For millions of keys, go with the Redis approach.
Challenge: Try It Yourself
Implement EXPIRE and PERSIST commands
Implement heap compaction to remove stale entries
Benchmark all three strategies with 100K keys
Next week: Why Redis Uses C, Not Python: The GIL Explained
Previous: Redis Persistence: WAL and Snapshots | Build Your Own Redis: Key-Value Store From Scratch